debian在window下的简单安装方法
下载win32-loader.exe,按照下一步定制自己的debian。
http://ftp.debian.org/debian/tools/win32-loader/stable/win32-loader.exe
A* 算法实现
https://github.com/imousewyfzml/mylibrary/blob/master/algorithm/AStar/myaStar.cpp
为了使用最大堆采用了multimap,并使用boost::lambda删除最大堆中value对应的key-value键值对.
可以读取map.txt地图,并将结果输出到map_res.txt.
如何删除git submodule子项
1. 编辑.gitmodules,删除对应要删除的submodule的行.
2. 编辑.git/config,删除有对应要删除的submodule的行.
3. 删除命令:
git rm --cached bundle/xxxx (PS:此处最后没有符号 / .)
4. 删除对应的目录:
rm -rf bundle/xxxx
wxPython-国际化设置
得益于gettext的支持,wxpython可以使用gettext库来让你的应用程序支持多国语,走向世界.在wxpython中有个比较方便的脚本mki18n.py,来自动生成.po和.mo.下面是一个自动生成的脚本:
gen_lang.sh放在你工程目录的lang或languages目录下,注意:这里生成的message.pot中的CHARSET已经要替换掉,否则程序无法执行,例如,替换成"UTF-8".
#!/bin/bash # mki18n.py依赖app.fil,里面是所有的py文件列表 find ../ -iname "*.py" -print >app.fil # 生成.po文件,domain一定要换成自己的 python mki18n.py -v -p --domain=your_application_name ./ # 上句命令,会生成message.pot文件,这个是一个模板文件. # 如果需要zh_CN的翻译,可以拷贝message.pot为 your_applaciton_name_zh_CN.po # 那么每次执行后就会生成your_applaciton_name_zh_CN.po.new,比较一下,合入新的未翻译的条目吧. # 生成.mo文件 # 这个会生成类似 # zh_CN/LC_MESSAGES/your_applaction_name.po python mki18n.py -m -e -v --domain=your_application_name --moTarget=./
在应用程序中,你只需要调用下面的install函数即可.
# coding: utf-8
import gettext
def install(localdir, lang):
gettext.translation("sgsgame", localedir=localdir, languages=lang).install(True)
例如:
# languages install
import util
langdir = os.path.join(home, "lang")
try:
util.i18n.install(langdir, ['zh_CN'])
except:
traceback.print_exc()
util.i18n.install(langdir, ['en_US'])
然后,应用程序中,所有 _()包括的字符串都会被翻译成中文,当然,前提是你已经在po文件中翻译好了.
参考连接: http://wiki.wxpython.org/Internationalization
Kernel中timer错误使用触发了BUG_ON
最近,AP终端老是重启,原因是timer中的cascade的BUG_ON语句被触发,这句BUG_ON的意思是检测挂在当前base数组中的timer,其结构中指向的base指针不是当前数组.按正常cascade,每次定时器因时间流逝,应该在切换base组的时候也切换自己内部的指针.这个base指针什么时候被改掉的呢?
static int cascade(struct tvec_base *base, struct tvec *tv, int index)
{
/* cascade all the timers from tv up one level */
struct timer_list *timer, *tmp;
struct list_head tv_list;
list_replace_init(tv->vec + index, &tv_list);
/*
* We are removing _all_ timers from the list, so we
* don't have to detach them individually.
*/
list_for_each_entry_safe(timer, tmp, &tv_list, entry) {
BUG_ON(tbase_get_base(timer->base) != base);
internal_add_timer(base, timer);
}
return index;
}
关于内核timer的使用,还要提到四个重要的接口:
add_timer, mod_timer, del_timer,init_timer.
函数名称已经很好的解释了函数的用法, 其中add_timer其实就是调用mod_timer,而mod_timer其实内部都调用了__mod_timer,那么__mode_timer做了那些事情呢?内核对mod_timer的注释说明了一切:
/** * mod_timer - modify a timer's timeout * @timer: the timer to be modified * @expires: new timeout in jiffies * * mod_timer() is a more efficient way to update the expire field of an * active timer (if the timer is inactive it will be activated) * * mod_timer(timer, expires) is equivalent to: * * del_timer(timer); timer->expires = expires; add_timer(timer); * * Note that if there are multiple unserialized concurrent users of the * same timer, then mod_timer() is the only safe way to modify the timeout, * since add_timer() cannot modify an already running timer. * * The function returns whether it has modified a pending timer or not. * (ie. mod_timer() of an inactive timer returns 0, mod_timer() of an * active timer returns 1.) */
可见,Init_timer后可以直接调用mod_timer来启动定时器.也可以在超时函数中调用mod_timer,以便形成周期定时器.del_timer用在模块退出或业务逻辑结束时,删除timer.
在Init_timer中,会对base重新赋值.代码如下:
static void __init_timer(struct timer_list *timer,
const char *name,
struct lock_class_key *key)
{
timer->entry.next = NULL;
timer->base = __raw_get_cpu_var(tvec_bases);
timer->slack = -1;
#ifdef CONFIG_TIMER_STATS
timer->start_site = NULL;
timer->start_pid = -1;
memset(timer->start_comm, 0, TASK_COMM_LEN);
#endif
lockdep_init_map(&timer->lockdep_map, name, key, 0);
}
排查代码发现应用程序可能调用ioctl的时候,内核中初始化了两次timer,导致正在运行的timer->base被修改.准确的说是我们使用timer的方法不正确.
1. init_timer尽量放在module初始化中
2. mod_timer在适当的时候调用,以便启动定时器.
3. del_timer在module退出或业务流程走完后删除.
另外,timer中BUG_ON也可能是SMP的硬件问题,具体可yahoo关键字"bug_on panic in cascade in timer.c"
wxPython-在主界面上放点东西
今天在主界面上放张风景图片吧,记得在学校上VC课程的时候,我们很喜欢把主窗体的背景搞的很漂亮,但是里面功能实现嘛,确实不敢恭维.能把图片放上面也算学到一些,先看wxPython怎么做到吧:
参与开源软件开发
使用linux近8年时光了,我从开源社区学到很多知识,从学会安装linux,到使用各种软件,从事linux应用软件开发,再到linux内核驱动.不仅是在学校,还是在工作中,开源社区对我帮助很大,感谢那些无私分享代码的牛人,但我却一直因生活奔波没有时间去回馈社区.<做一名开源社区的扫地僧>给我不少的启发,选择一个项目,参与进去,才能真正感受开源带来的财富,不管是物质还是精神层面上的.不管怎样,Just do it.
使用NAT共享上网
家里有一个台式机,但是没有无线网卡,必须使用网线连接路由器,但路由器在客厅,扯很长的网线很不方便.不过,我还有一台笔记本,上面装的是LINUX,所以想办法让台式机通过笔记本的eth口访问网络,那么就需要在笔记本上搭建一个NAT转发.
在linux上,使用IPtables轻松搞定这一切.组网图大致如下:
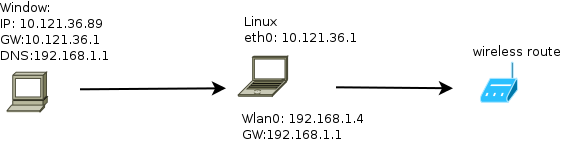
第一种方法:
IPtable设置如下:
# all interface
export WAN=wlan0
# 获取无线网口的IP地址
export WAN_IP=`ifconfig ${WAN} | grep "inet addr" | awk -F: '{print $2}' | awk '{print $1}'`
export LAN=eth0
# 获取路由器的地址
export REAL_GW=`route | grep default | awk '{print $2}'`
# remove all
# 清除NAT中的所有规则
iptables -t nat -F
# NAT settings
# 因为台式机(window)中的GW设置的是10.121.36.1,所以从笔记本上看LAN口收上来的包都是到10.121.36.1的,
# 这里就需要DNAT生效了,本质上是把数据包的目的地址给改掉,然后进入路由系统查找出端口
# 那么,下面这句话就是把去10.121.36.1的数据包,修改成${REAL_GW},这里是192.168.1.1
# 原有数据包头:
# SRC: 10.121.36.89 DST: 10.121.36.1
iptables -t nat -A PREROUTING -i ${LAN} -d 10.121.36.1 -j DNAT --to ${REAL_GW}
# 经过上面一句话后,变成
# SRC: 10.121.36.89 DST:192.168.1.1
# 然后,进入route table,找出端口,在笔记本(linux)上,192.168.1.1是default gateway.且是wlan0
# 所以数据包从wlan0走.
# 数据包终归要有ACK,如果192.168.1.1回应10.121.36.89这个地址的话,将找不到路由而在路由器上丢弃.
# 那么下面这句话,将源地址修改${WAN_IP},这里是192.168.1.4
iptables -t nat -A POSTROUTING -o ${WAN} -s 10.121.36.0/24 -j SNAT --to ${WAN_IP}
# 最终,出wlan0的数据包就是:
# SRC: 192.168.1.4 DST: 192.168.1.1
数据包从wlan口回来的时候就执行反操作.把数据发送给台式机(windows).
OK,一切正常.我不需要更复杂的设置了,如果大家有兴趣,请参考<更安全的linux网络>这本书.
第二种方法:
iptables -t nat -A POSTROUTING -s 10.121.36.0/24 -j MASQUERADE
网友依云http://lilydjwg.is-programmer.com/提供.
快速参考:
刘苏平的博客 http://www.liusuping.com/ubuntu-linux/iptables-firewall-setting.html
IPSec简介
介绍
IPsec是一种虚拟网络的应用,可以将internet虚成企业网来用,比如,公司在上海和北京都有办公区,两边为了能互相访问方便,一种解决方法是租用一条专用路线,物理上保证带宽和传输安全性,但是这样造价很高,有了VPN可以在inetenet上做一个逻辑层面上的网络,数据在彼此交换都使用AH或ESP方式对IP头部/载荷进行加密认证.这样保证了传输的安全性,但带宽就不好保证了, 总体来说VPN是较好的解决方案,节省成本.
工作模式
IpSec工作在两种模式下:传输模式, 隧道模式.区别与隧道模式,传输模式对IP头部不再次封装,而隧道模式会根据配置规则把原始数据包封装到一个新的IP数据包中.
加密方式
IPsec支持AH/ESP两种加密方式.
严格的来说, AH不是一种加密方式,而是对数据的校验或称数字签名.校验范围如下:
+------------+-----------+------------+
| ip header | AH header | ip payload |
+------------+-----------+------------+
| ------- verify scope ---------------|
发送过程中,增加一个AH头部,使用hash算法将IP头部+IP数据区进行校验生成fingerpoint,然后对fingerpoint加密填入AH header中.
这种校验方式可以防止数据传输过程被第三方篡改,但IP数据区的数据还是明文,并没有真正加密.
ESP则是真正意义上的加密.对数据加密后,数据区就会变成密文,无法直接识别,需要解密之后才能处理.